
What is observability?
Your software system is observable when the telemetry you collect and the way you process it enables you to know and investigate in a timely fashion how your software system is performing, what issues are occurring and what their impact is.

Observability vs. monitoring
Rather, observability through monitoring
The term "monitoring" is sometimes used to denote the collection and processing of metrics, and especially timeseries. Instead, we define monitoring more generally as the act and practice of collecting and processing useful telemetry to gain insight in the behavior of a system.
In the current practice of software, and especially in distributed systems and cloud-native software, monitoring is the commonplace means of achieving observability. Tools like Prometheus, OpenTelemetry, Jaeger, Elasticsearch or Graylog document the relevant workings of software systems by collecting and processing various telemetry types, such as metrics, distributed traces and logs.
Read our "Observability vs. monitoring debate: An irreverent view" blog post for an in-depth look at the debate around "observability vs. monitoring".
Monitoring and telemetry types
In today's open source monitoring practices, there are several types of telemetry being collected:
Metrics
Metrics are sets of related measurements of attributes of systems. In the scope of monitoring, usually metrics are collected as timeseries data with a numerical value (that is, numbers associated with timestamps), like how many requests have been served with a certain status code over the last minute. Besides numerical timeseries, boolean timeseries are also nowadays commonplace, like "is the service X up or not", as well as others with string-like values to represent, for example, "the value of configuration X at time Y."


Logs
Logs, structured (usually as JSON objects) or unstructured (as plain text following some pattern), are time-stamped entries that document the occurrence of an event like "the following error was caught" or "that payment process has been completed."
Distributed traces
Distributed traces document what work is done by various systems to process specific requests, like serving a Web page or executing a batch job. Nowadays, most distributed traces are modeled as a tree of spans. Spans are similar to structured logs, each describing some processing like "Serving request XYZ" or "Querying database 123", have a duration that reports how long it took to perform the processing, and have hierarchical relations to other spans in the form of child-parent relations. Usually, multiple systems contribute spans to one distributed trace, ranging from the API servers to databases and messaging queues and (micro)services in between.


Production profiling
Production profiling identifies hot spots of resource consumption by continuously sampling, with limited performance overhead, which parts of your application consume CPU cycles, memory and, depending on the runtime, the amount of wait time, or asynchronous wait. Production profiling is usually very useful in getting you started when troubleshooting latency and memory usage spikes in the absence of more detailed telemetry. The "production" reference is due to the tradeoffs in the design of the profiler to optimise for minimal overhead, as opposed to profilers used in development that tend to optimise for precision.
Real user monitoring
Real user monitoring is about collecting telemetry about user sessions occurring via interfaces like web pages, mobile applications and sometimes IoT devices; real user monitoring is closely related with distributed tracing, in which a user session is correlated with one or more distributed traces, each describing, for example, how one asset or XHR request is served to the user interface.


Synthetic monitoring
Synthetic monitoring checks are continuously test systems, mostly production ones, to ensure that particular APIs or even entire user flows in UIs, like a checkout process, work as intended; in other words, synthetic monitoring checks are smoke tests for APIs and UIs.
Telemetry correlation for deeper insights
Making the most out of your metrics, logs, distributed traces and more
The various telemetry types provide you with more insight when they are correlated with one another.
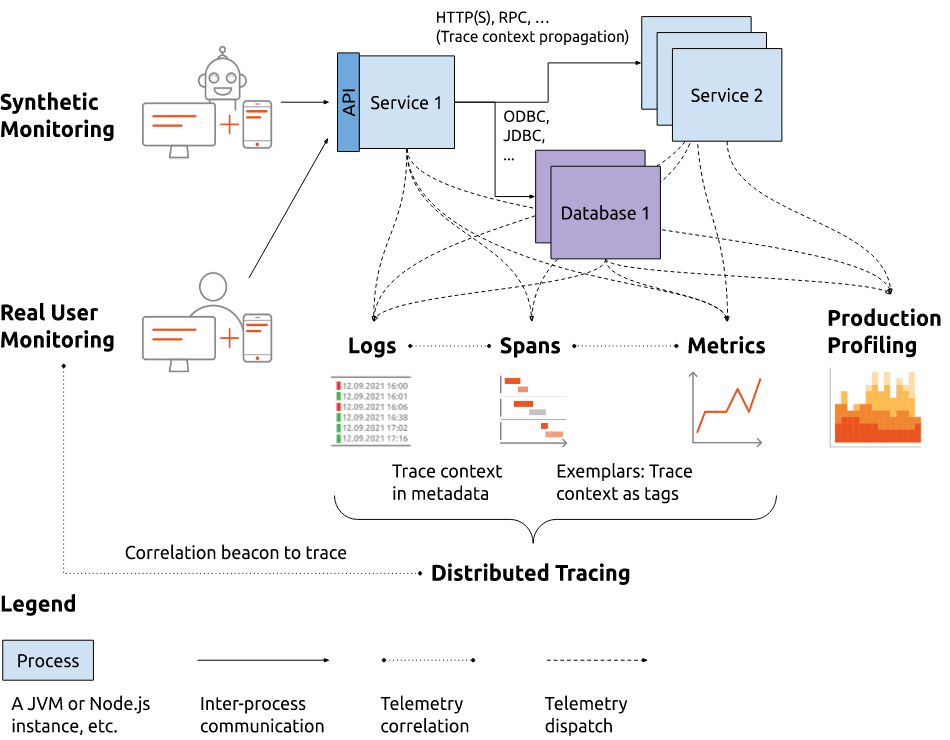
For example, Prometheus exemplars allow you to tag metrics with some sample distributed trace identifiers, so that you can drill down into some of the traces that affected specific metrics.
Another commonplace correlation of telemetry is adding the trace context identifier to the metadata of logs, so that you can go from viewing a single log to seeing the entire execution flow across all components and services involved in an event.
Telemetry context
An often underrated aspect of telemetry is its context; that is, which system is the telemetry coming from, where is that system running and, by extension, what is the relation (or lack thereof) between this piece of telemetry and others. You could think of this as correlating telemetry with the topology of the monitored systems.

Telemetry context is increasingly encoded via tagging: adding consistent, curated tags to timeseries metrics, logs, distributed traces and so on, so that one can filter all the available telemetry for that generated by a specific set of machines, processes or other system components in a specific time interval.
Another important function of telemetry context is to avoid confusion or outright mistakes when processing similar telemetry from unrelated deployments. For example, most alerting rules one may want to define for production databases should focus on specific clusters in specific regions, rather than "alert me when the 95th percentile of CPU usage across all my MySQL instances is above a threshold".
Controllability: observability in action
The forgotten twin to observability
The concept of observability originates in the field of modern control system theory, and its formulation has well withstood the test of time. And it was not a standalone concept either. Rather, observability had a twin concept, called controllability, which can be roughly defined as: "the property of a system to regulate itself and related systems to reliably produce the correct outputs given the provided inputs."
Nowadays, controllability is not a term many software engineers use daily, but its essence is embodied, for example, by operators implemented with Juju or other frameworks, which steer the software they operate and the infrastructure underneath to provide seamless configuration management and achieve scalability, reliability and graceful degradation.
Learn more about model-driven operationsDid you know?
The concept of observability was originally introduced by R. Kalman in 1960 in the field of modern control system theory, and its original meaning is largely still applicable to recent software, including cloud-native applications.
Ready to make your applications observable?
Canonical can support your open source observability stack with security fixes and LTS support, as well as run your best-of-breed, open source monitoring tools reliably and at scale.
More about open source observability