
What is real-time Linux? Part II

Edoardo Barbieri
on 28 February 2023
Tags: Industrial , real-time Linux

Welcome to this three-part mini-series on real-time Linux.
In Part I, we set the stage for the remainder of the series by defining a real-time system, and went through common misconceptions. We also covered the broad market applications of a real-time Linux kernel.
Several applications across a wide range of use cases and verticals require real-time computing capabilities. Sectors like industrial automation, energy and transportation have strict precision requirements for their systems. Similarly, telco network functions that facilitate traditional and modern real-time communications are not immune to jitter and delay.
If you missed it, head over to Part I to review the building blocks of a real-time system and learn about its market applications. If you are already familiar with the concepts and do not wish to refresh your memory, keep reading.
Here in Part II, we will delve deeper into the ins and outs of a real-time Linux kernel. To get started, we will discuss the concept of “preemption”.

Preemption and real-time Linux
“Preemption” lies at the core of real-time Linux. Preemption consists in temporarily interrupting the current thread of execution so that a higher-priority event can be processed in a timely manner. Increasing the preemptible code surface within the Linux kernel dramatically improves the capability to provide a deterministic response time to an external event. Let’s discuss the principles behind preemption in greater detail.
For our purposes, it helps to picture a process, which is nothing more than an instance of a program in execution, as the “execution context” of a running program. This process executes its sequence of instructions within a specific set of memory address spaces it is allowed to reference.
The system memory in the Linux kernel is segregated into kernel space and user space. The kernel space is the access-protected memory area reserved for executing the core of the OS in Kernel Mode, whereas user space is the system memory where user processes execute in User Mode.
The CPU cannot directly access the kernel extensions and data structures when application software executes in user space because of hierarchical protection domains. When a process executes in User Mode, it cannot directly access the kernel data structures or programs. On the other hand, these restrictions no longer apply when an application executes in so-called Kernel Mode.
Usually, a program executes in User Mode and switches to Kernel Mode only when requesting a service provided by the kernel. The Linux kernel then puts the program back in User Mode after satisfying the program’s request. To this end, each CPU model provides special instructions to switch from User Mode to Kernel Mode and vice versa.
Let’s now look at an example transition between User and Kernel Mode to clarify the importance of preemption.

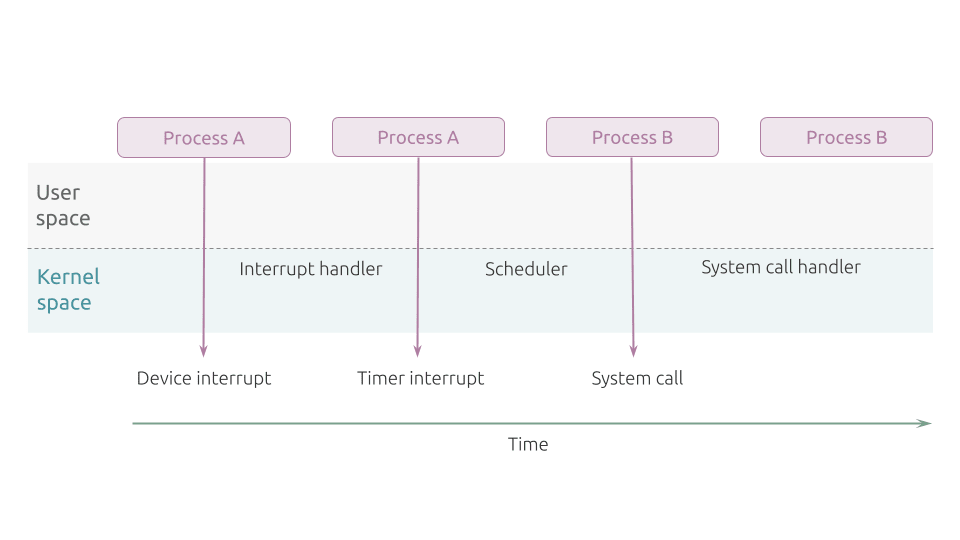
User space to kernel space transition
In the example Figure 1 below, Process A starts its execution in User Mode until a hardware device raises an interrupt. As a result, Process A then switches to Kernel Mode to service the interrupt. Having serviced the device interrupt, Process A can resume its execution in User Mode.
The running program continues in User Mode until a timer interrupt occurs, and the scheduler is activated in Kernel Mode. Now, a process switch occurs, and Process B starts its execution in User Mode.
Process B stays in User space until it issues a system call to access the kernel data structures: the process switches to Kernel Mode, and the system call can be serviced.
With no kernel preemption, tasks can’t be interrupted once they start executing code in the kernel or a driver. When a user space process requests a kernel service, no other task can be scheduled to run until that process either goes to sleep or until the kernel request is completed. Scheduling can only take place after the task voluntarily suspends itself in the kernel, or preemption can occur when the process exits it. What this means is that there is no deterministic response time, as one has to wait for the completion of the kernel request.
Making the kernel preemptible means that while one lower-priority process is running in the kernel, a higher-priority process can interrupt it and be allowed to run – even when the first has not completed its in-kernel processing. Hence, improving the flexibility to preempt tasks executing within the kernel helps to guarantee an upper time boundary.
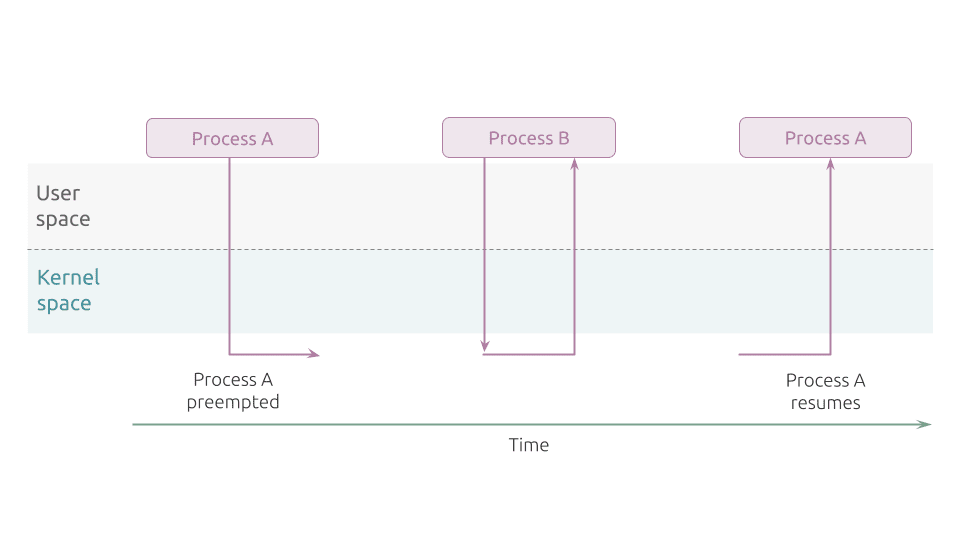
Let’s now look at a process switch in a Linux kernel with preemption capabilities.
In Figure 2, Process A entered the kernel. At this point, a higher priority Process B is woken up. The kernel then preempts the lower-priority Process A and assigns the CPU to Process B, even though Process A had neither blocked nor completed its kernel processing. The main characteristic of a preemptive kernel is that a higher-priority can replace a lower-priority one already running in Kernel Mode and while in the middle of a kernel function.
As argued in Part I, if the timing constraints of a real-time Linux system are not met, system failure is said to have occurred. Without kernel preemption, there can be no real-time compute in Linux. While in the early Linux days of Linux 1.x kernel preemption did not exist, several attempts to bring preemption into the kernel have been proposed through the years and made their way into mainline Linux. Linux introduced kernel preemption only with version 2.5.4 [1].
As we will clarify in Part III, the different preemption models available directly affect the real-time compute capabilities of the Linux kernel. Furthermore, the challenge in making a preemptible kernel lies in identifying all critical sections within the kernel that must be protected from preemption. In the concluding piece of this mini-series, we will assess those difficulties and how to overcome them.
Further reading
In Part I of this three-part series on real-time Linux, we covered the definition of a real-time system, the common misconceptions that arise when discussing real-time Linux, and its key market applications and use cases. In this blog, we discussed how increasing the preemptible code surface within the Linux kernel is the cornerstone behind providing a bounded response time to an external event.
In the final blog, we will study the different preemption models available in mainline, introduce the PREEMPT_RT patchset and look at the latest announcement of Real-time Ubuntu.



Talk to us about real-time Ubuntu
Interested in running real-time Ubuntu in production? Tell us more about your needs
Newsletter signup
Related posts
Meet Canonical at SPS 2024
SPS (Smart Production Solutions) 2024 is almost here! With over 1,200 national and international exhibitors, SPS is the main gathering of industrial...
Canonical releases Real-time Ubuntu 24.04 LTS
London, 30 May 2024. Today Canonical announced the availability of Real-time Ubuntu 24.04 LTS. By ensuring high-priority processes are executed first, with...
Real-time Linux vs RTOS – Part II
Download our latest Whitepaper: A CTO’s Guide to Real-time Linux Welcome to this two-part blog series on real-time systems which asks the question: Real-time...