
Building a comprehensive toolkit for machine learning

Andreea Munteanu
on 24 November 2023
In the last couple of years, the AI landscape has evolved from a researched-focused practice to a discipline delivering production-grade projects that are transforming operations across industries. Enterprises are growing their AI budgets, and are open to investing both in infrastructure and talent to accelerate their initiatives – so it’s the ideal time to make sure that you have a comprehensive toolkit for machine learning (ML).
From identifying the right use cases to invest in to building an environment that can scale, organisations are still searching for ways to kickstart and move faster on their AI journeys. An ML toolkit can help by providing a framework for not just launching AI projects, but taking them all the way to production. A toolkit aims to address all the different challenges that could prevent you from scaling your initiatives and achieving the desired return on investment.
What is an ML toolkit and why do you need one?
A machine learning (ML) toolkit represents all the necessary tools and skills that organisations need to get started and scale their ML initiatives. It includes different aspects of the machine learning lifecycle, but it goes beyond to also take into account the capabilities that are needed to efficiently build models, push them to production and maintain them over time.
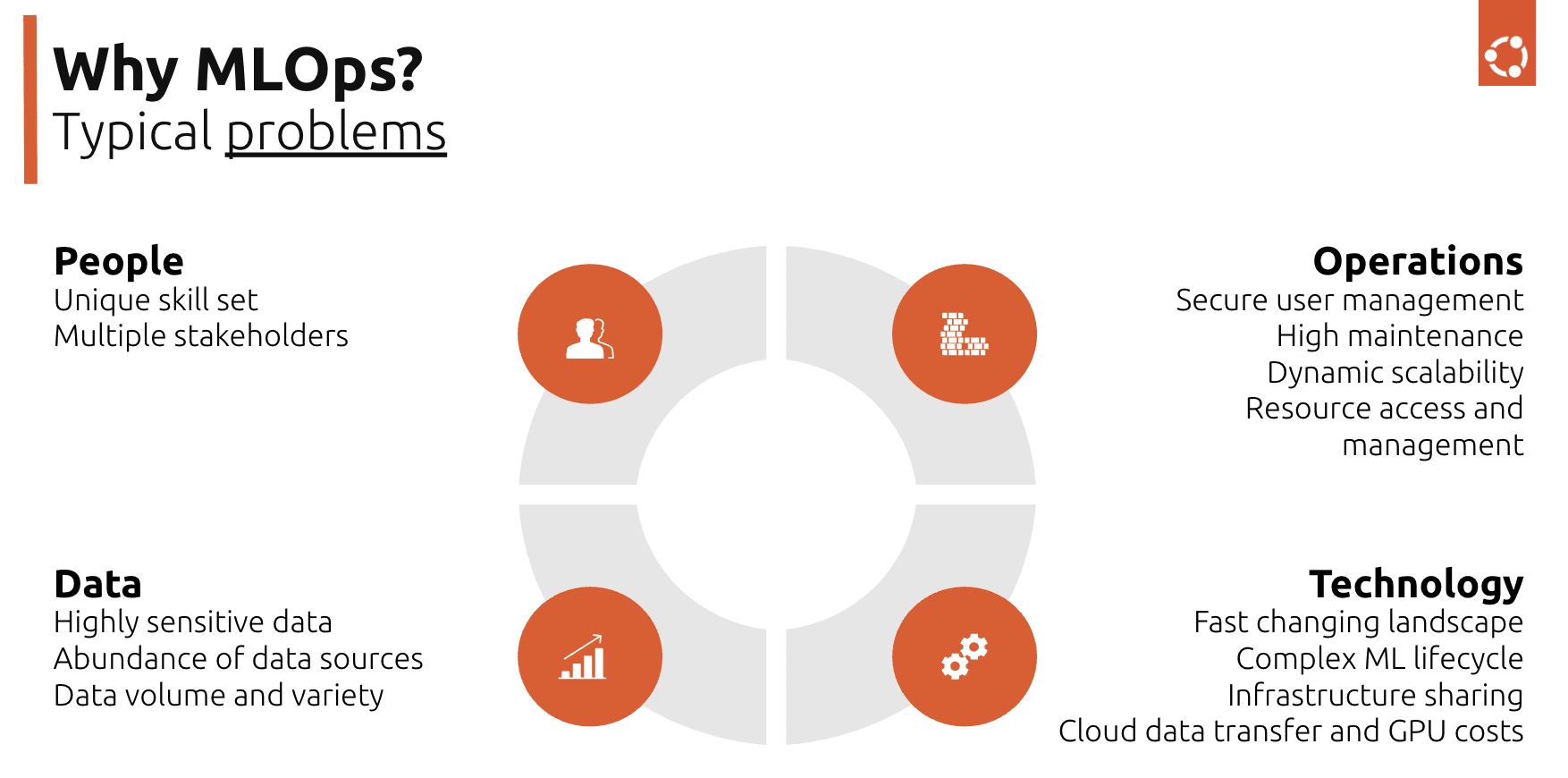
There are multiple challenges that companies need to address when they start looking at an AI project. These can be grouped into four main categories:
- People: There is a skills gap on the market that makes hiring difficult. AI projects also have multiple stakeholders that can slow down the project delivery.
- Operations: Scaling up a project is difficult, mainly because of the associated operational maintenance costs.
- Technology: There is a fast-changing landscape of new tools, frameworks and libraries that teams need to consider. Identifying the right choices is often overwhelming.
- Data: Both the continuous growth of data volumes and the need to deal with highly sensitive data are concerns that keep teams up at night.
The machine learning toolkit looks at many of these areas and helps organisations build an end-to-end stack that addresses the entire machine learning lifecycle. It considers the hardware layer, as well as the software that goes on top of it, trying to optimise operations and automate workloads. The toolkit enables professionals to securely handle high volumes of data, as well as leverage different types of architectures depending on where the organisation is in their AI journey. Capabilities such as user management, security of the infrastructure or the compute power needed will be further detailed as part of the toolkit.
What goes into a toolkit for machine learning?
Organisations often look only at the computing power needed or the machine learning tooling that’s available to define the toolkit. While those are important, they are only two pieces of the puzzle. Building and scaling an AI project requires additional resources, including the cloud, container layer, and MLOps platform. MLOps engineers and solution architects need to bear in mind that any project, even if it starts small, will likely scale over time. Therefore, they need a toolkit that gives them the flexibility to add additional tools or compute power to the stack.
Let’s explore the key components of an ML toolkit.
Compute power for machine learning
There’s no denying that compute power is central to AI/ML projects, and it is an essential part of an effective toolkit. This is the main reason AI/ML projects have traditionally been considered high-cost. This is also the very first challenge that organisations identify when it comes to AI projects, assuming often that they need a very powerful stack in order to begin their AI journey. This goes hand in hand with the scarcity of graphical processing units (GPUs) that exists on the market, which has delayed many projects.
Nowadays, this paradigm is beginning to shift as chipsets become more performant and market leaders launch dedicated infrastructure solutions, such as NVIDIA DGX, which empower enterprises to build and scale their AI ecosystems on proven platforms. With NVIDIA DGX now available on Microsoft Azure Marketplace, we are likely seeing the start of a new era for compute power, where organisations will not view it as a bottleneck for AI projects, but rather an accessible component of their ML toolkit.
Learn how to run AI at scale with Canonical and NVIDIA.
Download the whitepaperClouds for machine learning
All the compute power in the world won’t help if you don’t have the means to store all the data it will be processing. Thus, cloud computing is a natural fit for AI and a crucial component of the toolkit. It takes the burden of provisioning away from solution architects, enabling them to spin down or turn on large-scale clusters with little downtime. While the experimentation phase requires fewer resources, building enterprise-ready models requires serious computing resources. In order to overcome this barrier, companies take different approaches which have pros and cons.
This part of the toolkit can be built in different ways. Often, organisations will:
- Build their own infrastructure (or private cloud): Solutions such as Charmed Openstack are a great example of a cloud platform that can be used to build and deploy machine learning applications. It is a cost-effective platform that provides enterprise-grade infrastructure for machine learning workloads.
- Benefit from the public cloud computing power: Machine learning projects are usually run on public clouds because of the low initial cost. Google, Amazon and AWS have different pricing models and offer different types of instances. This diversity in instances is beneficial to companies, as their compute needs vary depending on the amount of data and model training requirements.
- Choose a hybrid cloud: Hybrid clouds unlock the value of data. Data is spread across different clouds and data complexity continues to increase. Hybrid clouds give the necessary flexibility and accessibility to address this complexity. They offer the data foundation needed to scale and operationalise AI, enabling models to be better fed with data, regardless of where it is stored, leading to better accuracy.
- Build a multi-cloud scenario: Generative AI is just one of the drivers accelerating multi-cloud adoption, due to the extremely large datasets. Multi-clouds are great because organisations can use the strengths of different clouds to optimise their machine learning projects.
Choosing the right cloud is often a challenge for organisations. Between the initial cost and the potential to scale, it’s easy to feel lost. When choosing the cloud, enterprises should bear in mind their AI readiness, as well as the security and compliance requirements. Also, in order to optimise the cost, they should leverage their existing infrastructure and build around it, rather than start a completely new one for their AI projects.
Kubernetes for machine learning
The ML world relies heavily on cloud-native applications its important to include a container platform in your ML toolkit. As the world’s leading container orchestration platform, Kubernetes is an ideal fit. At the outset of a project, Kubernetes enables reproducibility and portability, and as projects grow, Kubernetes becomes invaluable for scalability and resource management.
For enterprises that already have a private cloud deployed, Kubernetes is also an option to simplify and automate machine learning workloads. There are many different flavours of Kubernetes available, so it’s important to choose a distribution that is suitable for enterprise AI projects. Canonical Kubernetes can be used as an extension of Charmed OpenStack, enabling enterprises to kickstart AI projects on their existing infrastructure while benefiting from enterprise support.
Machine learning tooling

This might be the most obvious part of the toolkit, but also the most deceptively difficult The machine learning landscape is growing from one day to another, reaching an enormous size. There are so many logos, options and projects that choosing the right tooling can be one of the biggest challenges when building out your toolkit. – especially when what you should really be looking for is a machine learning operations (MLOps) platform.
MLOps is shortly defined as DevOps for machine learning. It ensures the reliability and efficiency of the models. Rather than looking at individual tools, what enterprises actually should include in the ML toolkit is an MLOps platform that consolidates tooling and processes into a single environment.
Open source MLOps gives you access to the source code, can be tried without paying and allows for software contributions. AI/ML has benefited from upstream open source communities since its inception. This led to an open source MLOps landscape with solutions spanning various categories such as:
- End-to-end platforms: Kubeflow, MetaFlow or MLFlow
- Development and deployment: MLRun, ZenML or SeldonCore
- Data: Being the core of any AI project, this category itself can be further split into:
- Validation: Hadoop, Spark
- Exploration: Jupyter Notebook
- Versioning: Pachyderm or DVC
- Testing: Flyte
- Monitoring: Prometheus or Grafana
- The scheduling system: Volcano
To sum up…
A machine learning toolkit goes beyond the ML tools that are used. Whereas kickstarting an ML project might be easy, scaling an initiative requires further capabilities across both the hardware and software components. To guarantee the smoothest path to production, you need a comprehensive toolkit that can support you throughout the entire AI journey.
Assembling a toolkit for machine learning can be a challenging undertaking, which is why we have produced a guide detailing our recommendation for an end-to-end toolkit.
Further reading
Run Kubeflow anywhere, easily
With Charmed Kubeflow, deployment and operations of Kubeflow are easy for any scenario.
Charmed Kubeflow is a collection of Python operators that define integration of the apps inside Kubeflow, like
katib or pipelines-ui.
Use Kubeflow on-prem, desktop, edge, public cloud and multi-cloud.
What is Kubeflow?
Kubeflow makes deployments of Machine Learning workflows on Kubernetes simple, portable and scalable.
Kubeflow is the machine learning toolkit for Kubernetes. It extends Kubernetes ability to run independent and
configurable steps, with machine learning specific frameworks and libraries.
Install Kubeflow
The Kubeflow project is dedicated to making deployments of machine learning workflows on Kubernetes simple,
portable and scalable.
You can install Kubeflow on your workstation, local server or public cloud VM. It is easy to install
with MicroK8s on any of these environments and can be scaled to high-availability.
Newsletter signup
Related posts
AI in 2024 – What does the future hold?
AI in 2024
What is MLflow?
MLflow is an open source platform, used for managing machine learning workflows. It was launched back in 2018 and has grown in popularity ever since, reaching...
A deep dive into Kubeflow pipelines
Widely adopted by both developers and organisations, Kubeflow is an MLOps platform that runs on Kubernetes and automates machine learning (ML) workloads. It...